
2022年3月科研月报(人工智能版)
目录
- 本学期科研规划
- 本月规划
- 第一周 2022/02/28 – 2021/03/06
- 第二周 2022/03/07 — 2022/03/13
- 第三周 2022/03/14 — 2022/03/20
- 第四周 2022/03/21 — 2022/03/27
本学期科研规划
学习《动手学深度学习》课程,尽快入门学会深度学习基本知识和编程。
本月规划
阅读深度学习论文,学习网课,学会CNN相关知识。
第一周 2022/02/28 – 2021/03/06
本周工作情况和进展
写论文
完善区块链论文(在本周报不展开说明)阅读论文
本周阅读了三篇论文(上周遗留的一篇):
Machine Learning Models that Remember Too Much:利用网络隐藏信息,设计到部分信息隐藏知识
Overlearning Reveals Sensitive Attributes:神经网络记录信息过多,包括各种敏感信息,可以利用特征推导敏感属性,或者将模型重训练来预测敏感属性
Adversarial Learning of Privacy-Preserving and Task-Oriented Representations:对抗训练模型保护隐私,使解码器效果变差。运行实验
本周初步运行了论文《Neural Network Inversion in Adversarial Setting via Background Knowledge Alignment》中的攻击实验。
针对猜想:模型越小,反演攻击效果是否越差?进行三组实验,分别设置模型ndf为128(loss1橙色)、64(loss2蓝色)、5(loss5红色),进行100轮训练,损失变化和对比如下图: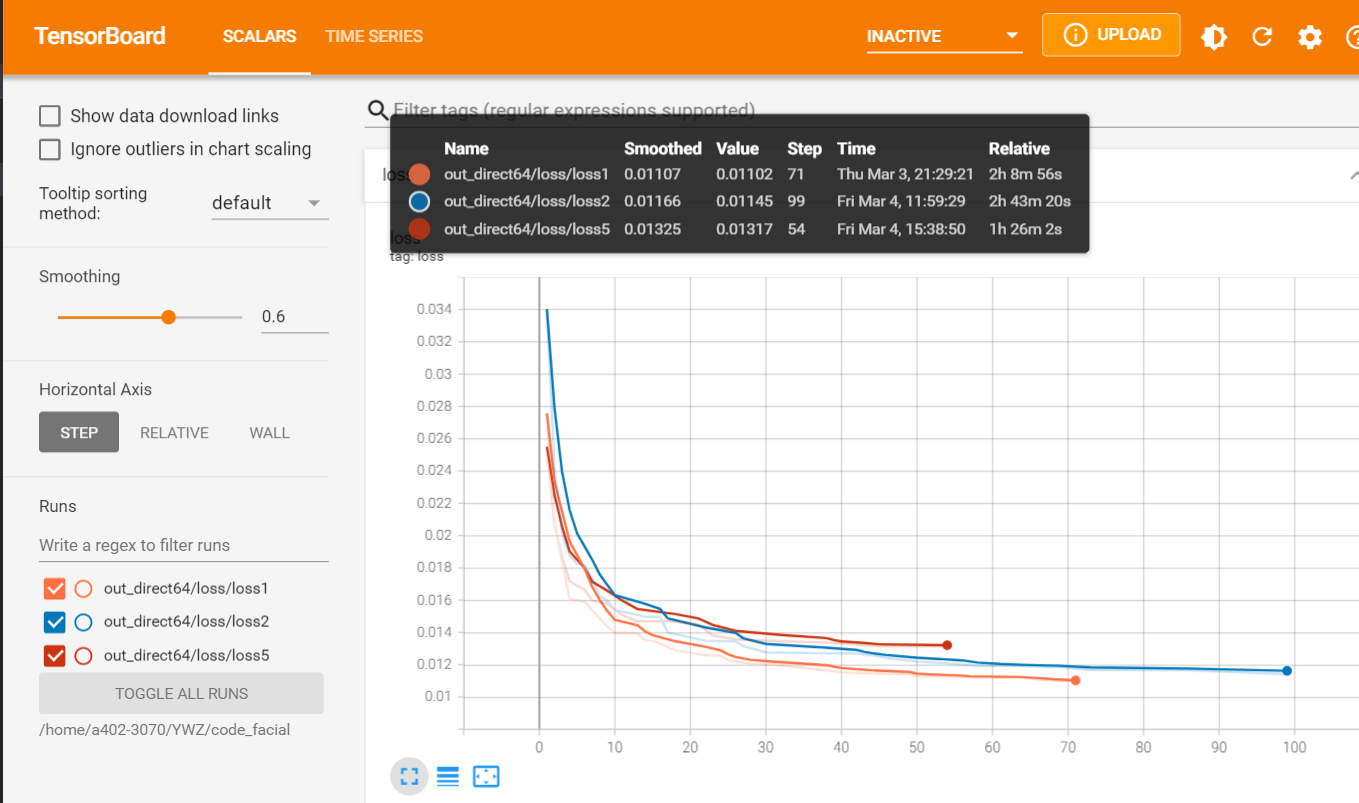
虽然随着模型变小,攻击的损失会增大,效果变差,但是差距不大,loss差距在0.002左右,并且图片对比差距也很小。因此得出初步结论:攻击效果与模型大小没有较强关系。
二,存在的问题
本周阅读论文、运行实验时,并不能很好理解代码和公式,尤其是CNN相关内容。缺乏CNN知识。
三,下周工作计划
- 学习CNN视频
- 阅读新的论文
- 运行上周论文实验
第二周 2022/03/07 — 2022/03/13
一,本周工作情况和进展
阅读论文
本周阅读了两篇论文:
The Secret Revealer: Generative Model-Inversion Attacks Against Deep Neural Networks:通过GAN来生成图片,并恢复图像中的敏感数据。
Model inversion attacks against collaborative inference:虽然标题是合作推理,但就是partition的场景下进行模型反演攻击,分别在白盒场景、可query黑盒场景、不可query黑盒场景下进行测试。学习网课
本周学习了《动手学深度学习》16节-21节的内容,重点是卷积层,理解了图像卷积的操作,以及通道、填充、步幅、卷积核等超参数的作用。
二,存在的问题
第一篇论文中有多个loss公式没看懂。
第二篇论文中。白盒场景虽然可以获得参数,但并没有使用,构造了x0,减少f(x0)和f(x)的loss(3a),同时使用(3b)公式计算图片的平滑度,从而使构造的x0逼近原输入x
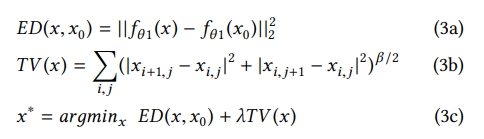
可是这样不还是黑盒吗?个人比较疑惑,可以在下周开会时进行探讨。
三,下周工作计划
- 继续学习CNN
- 阅读论文
- 能够改一改代码,跑实验
第三周 2022/03/14 — 2022/03/20
一,本周工作情况和进展
阅读论文
本周阅读了两篇论文:
Property Inference Attacks Against GANs:对GAN进行属性推理攻击,分为全黑盒(输入随机)和部分黑盒(可以控制输入的特征向量)攻击,部分黑盒攻击时训练多个影子GAN模型,两种攻击都训练额外的分类器对GAN的输出进行分类,并根据分类结果推测属性占比。本论文的测试非常丰富,包含各种影响因素,如训练样本数、影子模型数、分类器结构和数据分布等。
Attacking and Protecting Data Privacy in Edge–Cloud Collaborative Inference Systems:该篇论文和上周论文的理论部分完全一致,属于会议论文修改30%再投期刊,但两篇论文测试不同,本论文重点测试防御方法,如加噪音、在不同层采用丢弃法、模型分割位置等,在中间层加噪音、更深的层采用丢弃法、在更深的层进行分割(至少包含一个全连接层),防御效果更好。实验
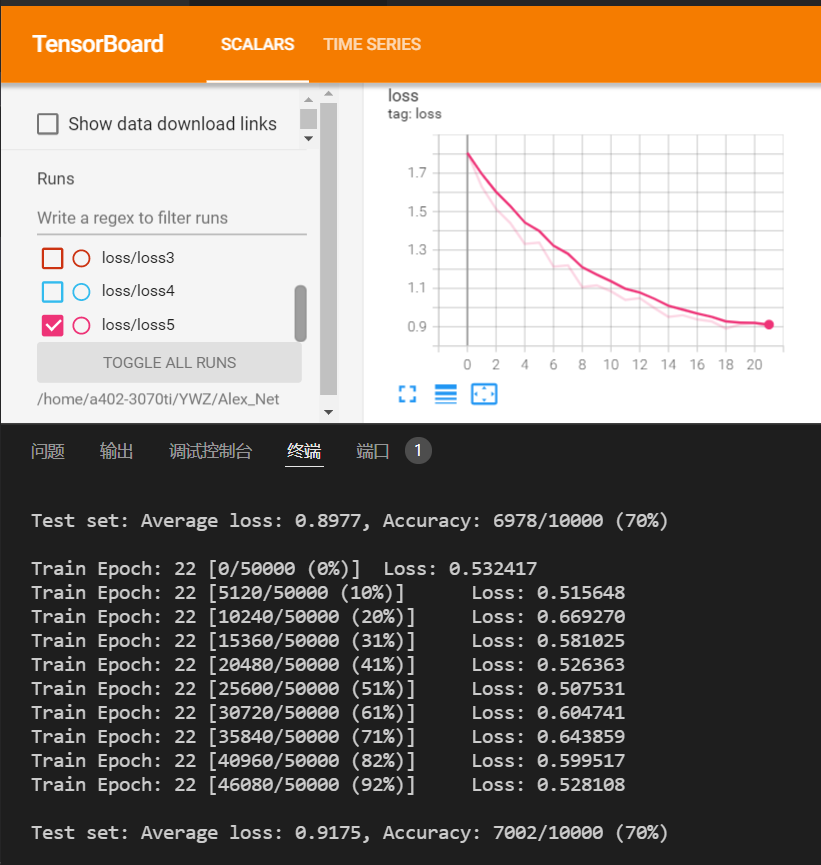
编写AlexNet,并对CIFAR10数据集进行测试。
原AlexNet针对的是3x224x224的图片,卷积层会压缩到非常小,而CIFAR10是3x32x32的大小,需要更改网络参数。
测试结果如下: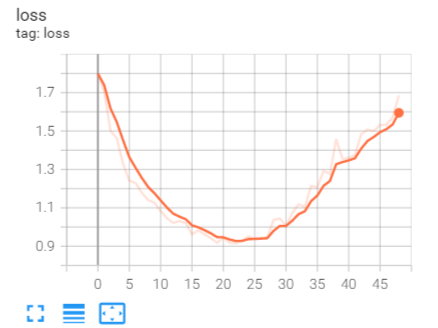
训练50轮时会有严重的过拟合,训练到23轮左右可以得到最低的loss,准确率为70%。
二,存在的问题
第一篇论文是针对GAN的属性推理攻击,但在最后迁移到了成员推理攻击,该部分没看懂,尤其是三个公式。
三,下周工作计划
- 阅读论文
- 学习自注意力机制
第四周 2022/03/21 — 2022/03/27
一,本周工作情况和进展
阅读论文
本周阅读了两篇论文:(任务有三篇,但截止到27号有一篇没看完)
Updates-Leak: Data Set Inference and Reconstruction Attacks in Online Learning:在模型更新场景下窃取更新数据集label或者重构数据集。在黑盒场景下,设置四种攻击,单例更新集推测label,单例更新集重构,多例更新集推测label分布,多例更新集重构。四种攻击都采用了AutoEncoder类似架构,而在多例更新集重构中使用Generator作为Decoder,并使用聚类方法来进行选择重构图像。
ActiveThief: Model Extraction Using Active Learning and Unannotated Public Data:使用与目标模型同类型同内容的公开数据集作为query数据,在query后使用四种子集选择策略选择下一次query的数据。实验
本周使用了Attacking and Protecting Data Privacy in Edge–Cloud Collaborative Inference Systems论文中的Dropout防御方法,dropout用在vgg,并对dropout率进行测试,结果如下:
| Dropout Rate | 分类准确率 | 反演ssim |
|---|---|---|
| 0.5 | 85.2 | 0.6 |
| 0.7 | 84.26 | 0.46 |
| 0.8 | 83.63 | 0.36 |
| 0.9 | 81.84 | 0.2 |
- 网课学习
本周匆忙地学习了注意力相关内容,初步了解相关含义,但注意力例子都是在seq2seq上的,transformer也是,因此不是很理解,需要补充seq2seq相关知识。
二,存在的问题
- Updates-Leak:多个更新集中,不理解推测label分布,获得各label数目?在多例更新重构中,Best-Match loss中前一个是交叉熵损失,越小越好,后一个是Discriminator判别结果,这个应该越大越好,不理解为什么是相加。
- ActiveThief:只是添加了选择策略,loss使用目标网络和影子模型的label差异,感觉只是训练了一个功能相似的模型,对窃取的效果感到怀疑。
三,下周工作计划
- 学习网课
- 完成论文阅读
- 完成Dropout实验